Trawl
Trawl is a web platform that turns scattered, unstructured customer feedback into a structured and prioritized product roadmap. Users connect feedback sources such as App Store and Google Play reviews, Reddit threads, CSV exports, or pasted text, and Trawl ingests, chunks, and embeds that feedback into a pgvector database. A Retrieval-Augmented Generation pipeline then lets users query their feedback in natural language, auto-generates structured feature specs and user stories grounded in real customer evidence, and runs a flagship 'What Should We Build Next?' analysis that clusters feedback into themes and ranks them into a prioritized roadmap. Every generated spec stays fully traceable: a RAG transparency panel shows the exact feedback chunks retrieved, their cosine-similarity scores, and how each one informed the output. Results land on an interactive, drag-and-drop Kanban board.

Trawl's landing page — type an app name to get a roadmap. The platform pulls live reviews from the App Store, Google Play, and Reddit, and turns them into a prioritized product spec list.
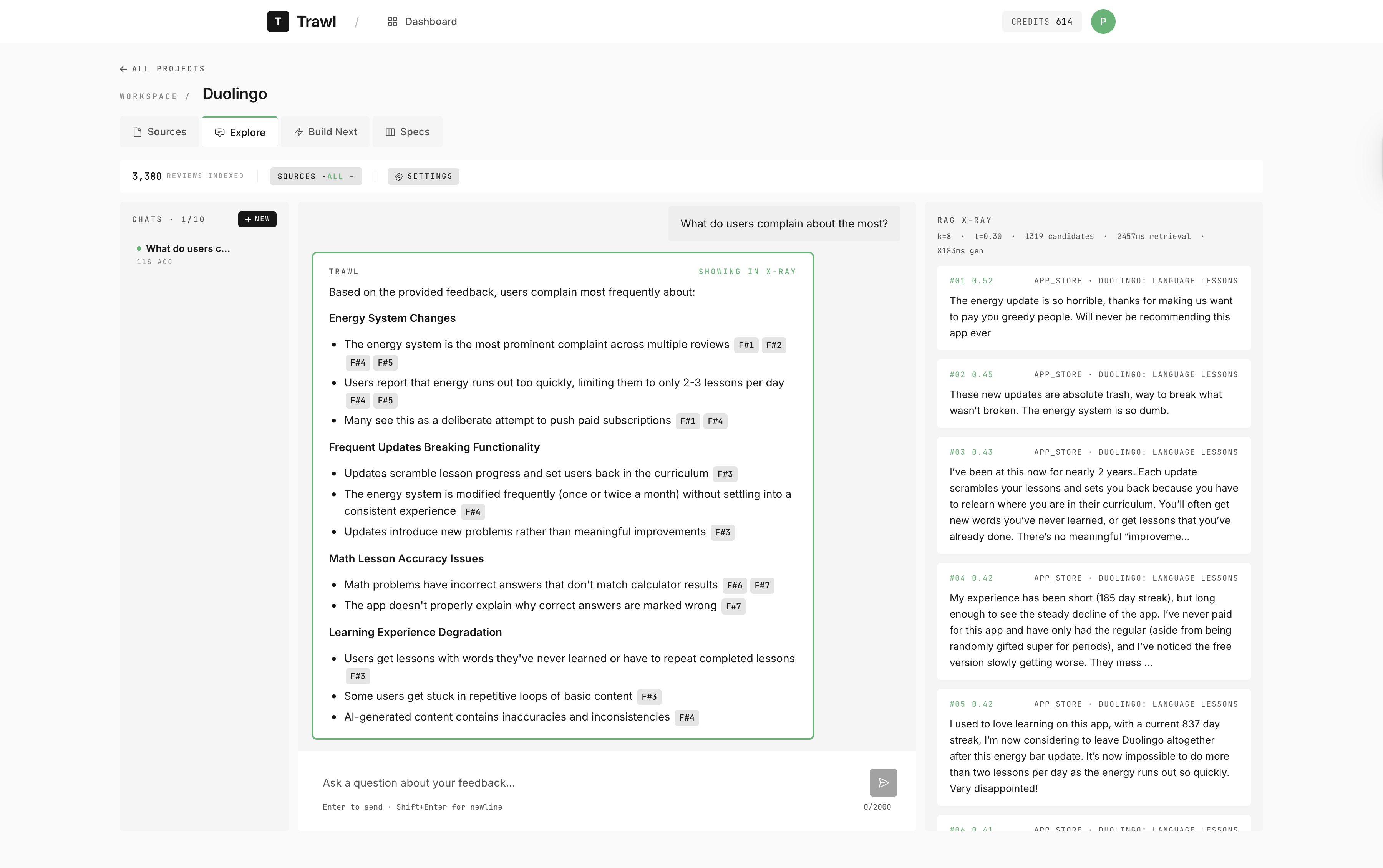
The RAG X-Ray panel — every answer is grounded in real reviews. Inline citation badges point to the exact feedback chunks the retrieval surfaced, and the side rail shows each chunk with its cosine similarity score, so users can audit how the answer was built.
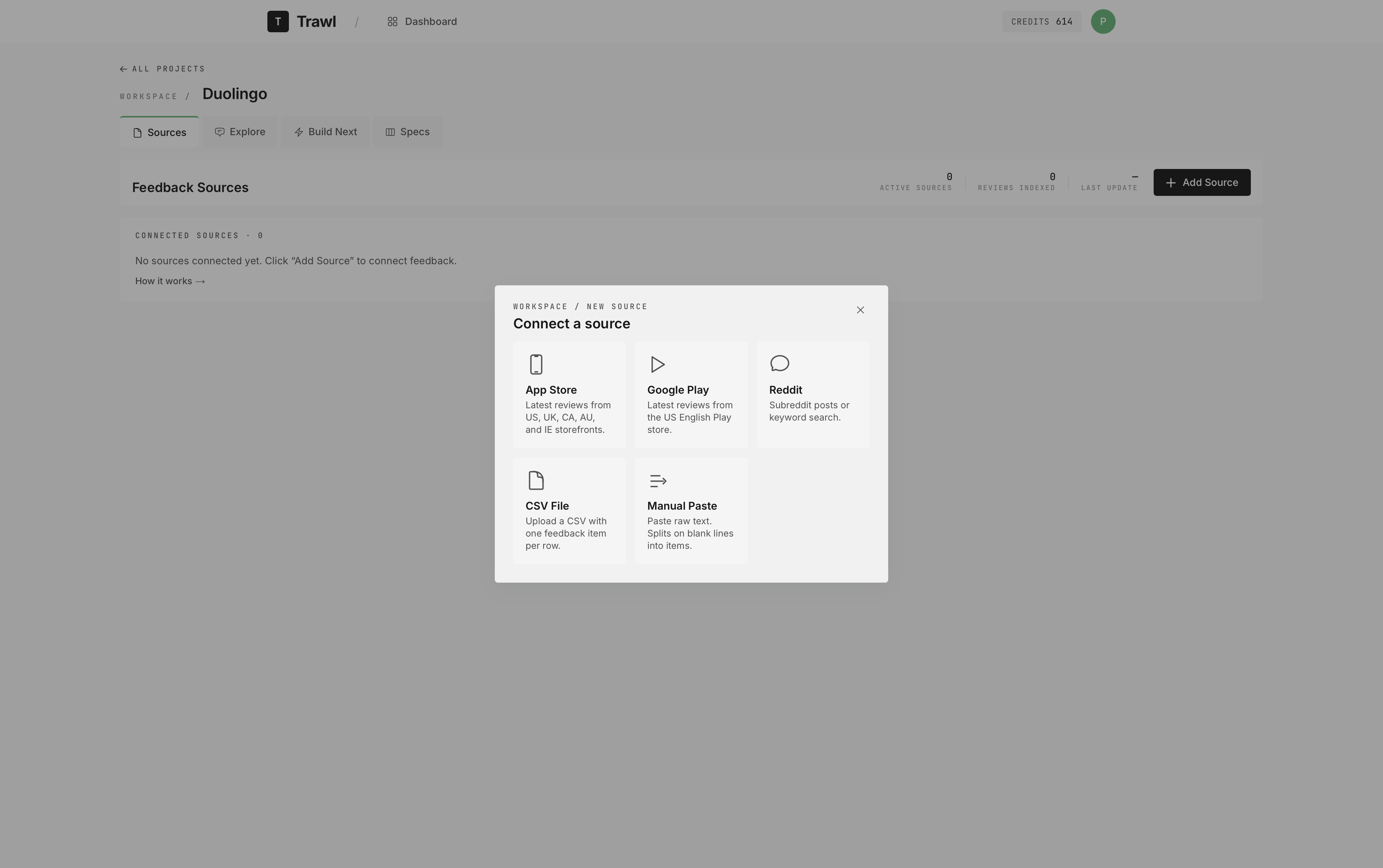
Five live connectors plus CSV and manual paste. Adding a source kicks off a four-stage Celery pipeline that scrapes, chunks, embeds, and indexes the feedback automatically.
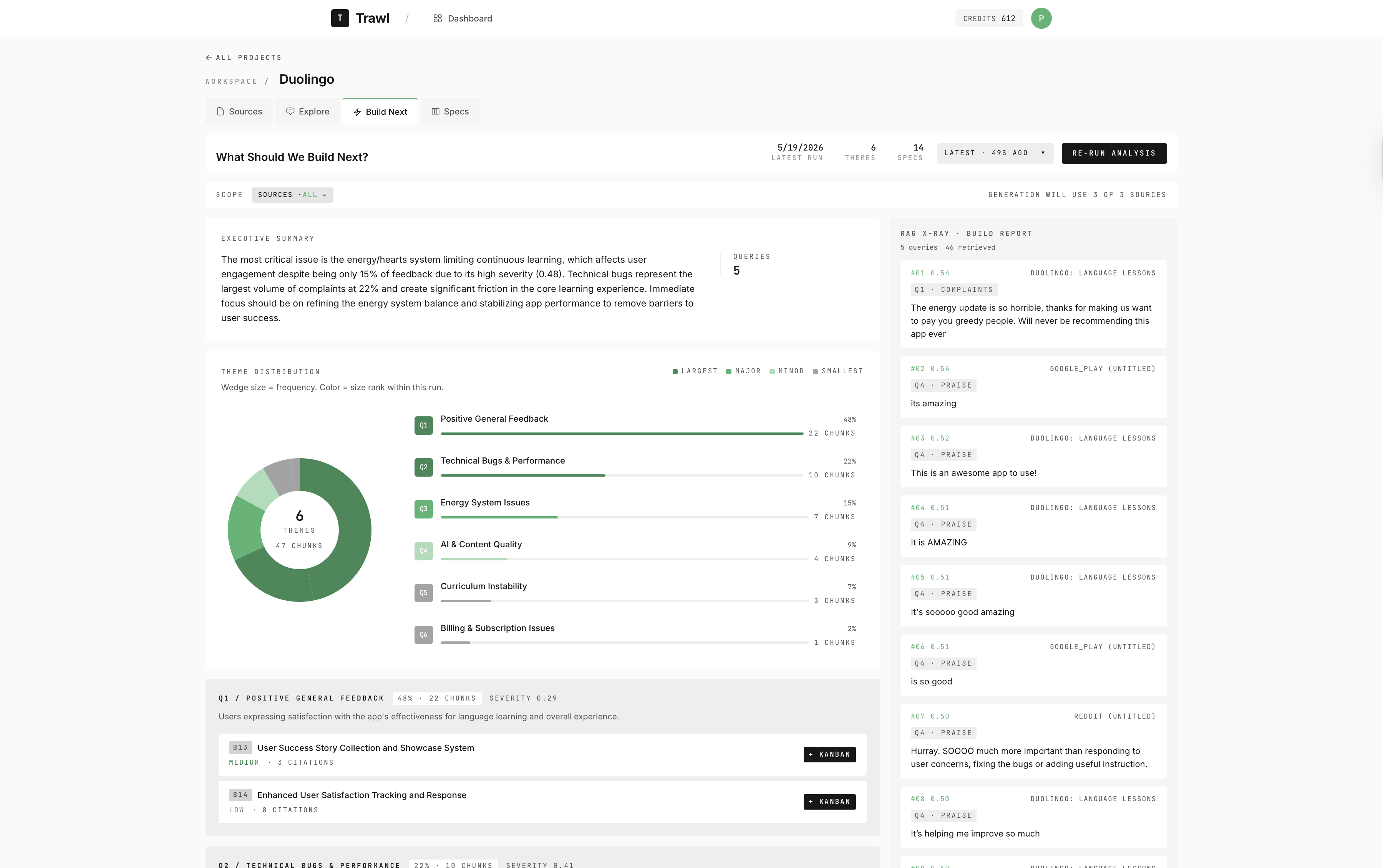
The 'What Should We Build Next?' engine — runs five exploratory queries over the full corpus, clusters the results into themes scored by frequency and severity, and outputs a prioritized list of spec drafts alongside an executive summary. Per-query attribution badges in the X-Ray rail trace each chunk back to the query that surfaced it.
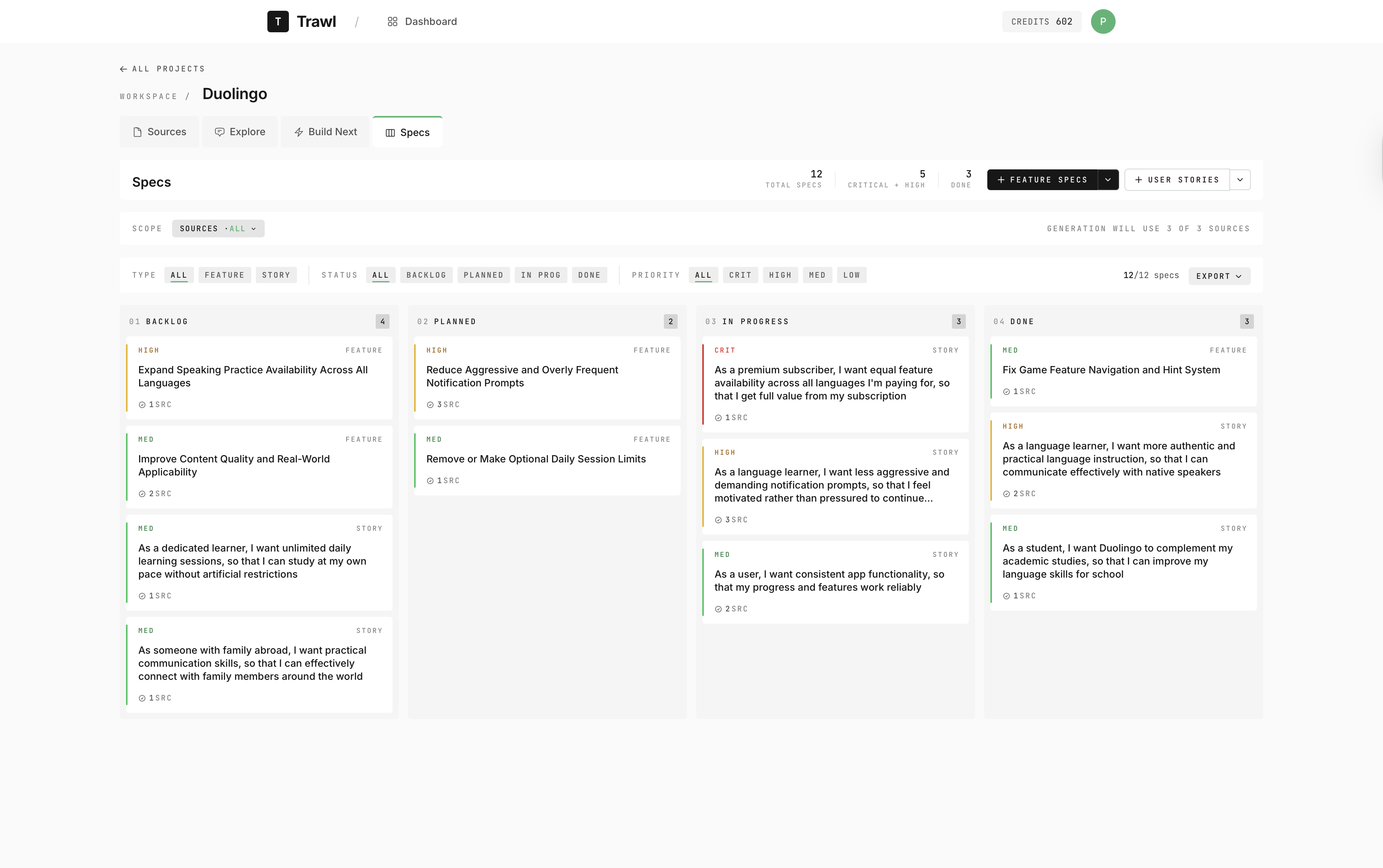
Generated specs land on a drag-and-drop board with four status columns and color-coded priority. Every card carries a citation count back to the source feedback that produced it.
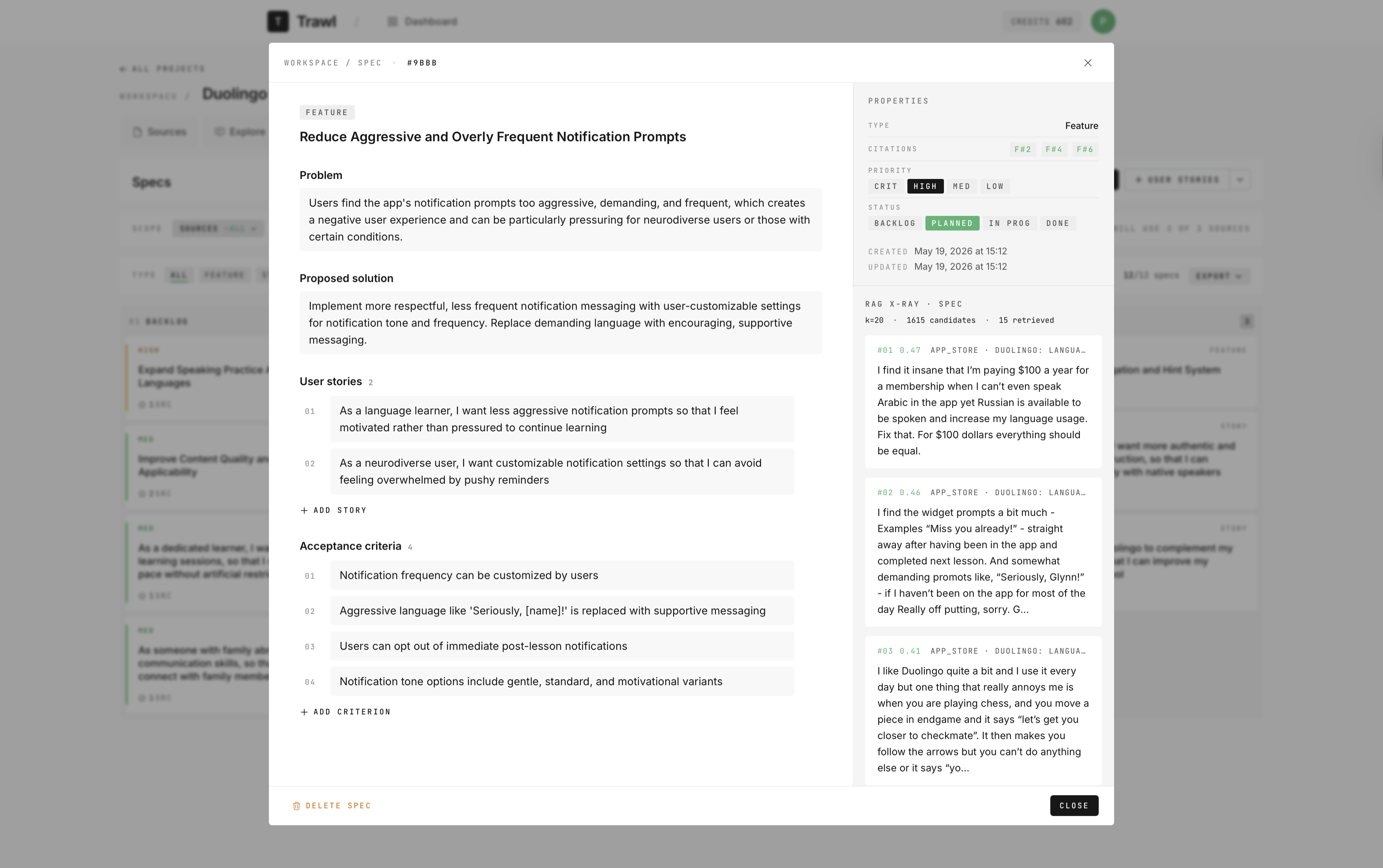
Spec detail view — open any card to inspect the full spec: problem, proposed solution, user stories, and acceptance criteria. Citation chips sit on every claim, the retrieved feedback shows in a side rail, and every field is editable inline.
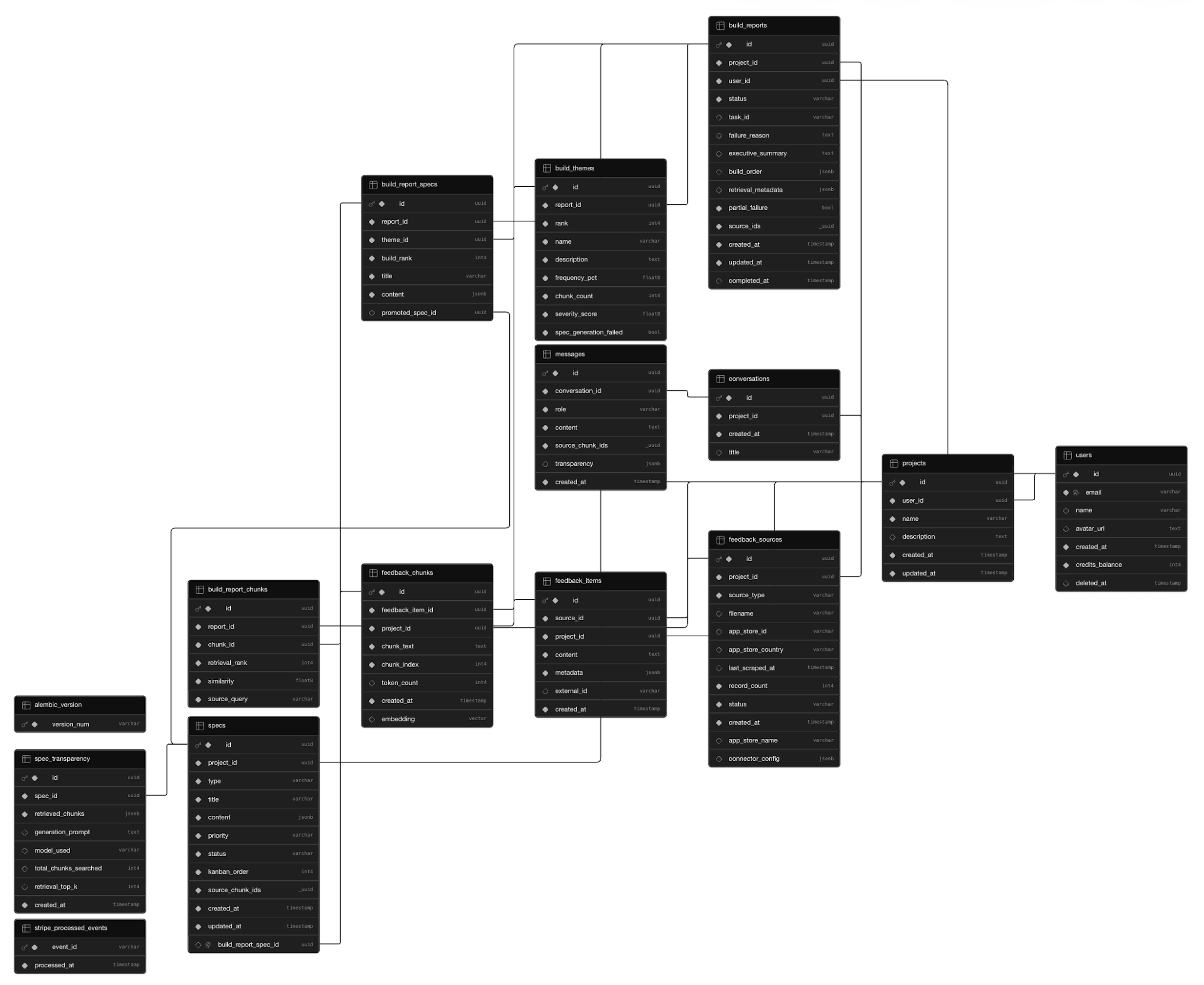
The Postgres schema across 14 tables, with pgvector embeddings as a first-class column on feedback chunks. Build Next runs persist as a four-table family so users can time-travel between past analyses.